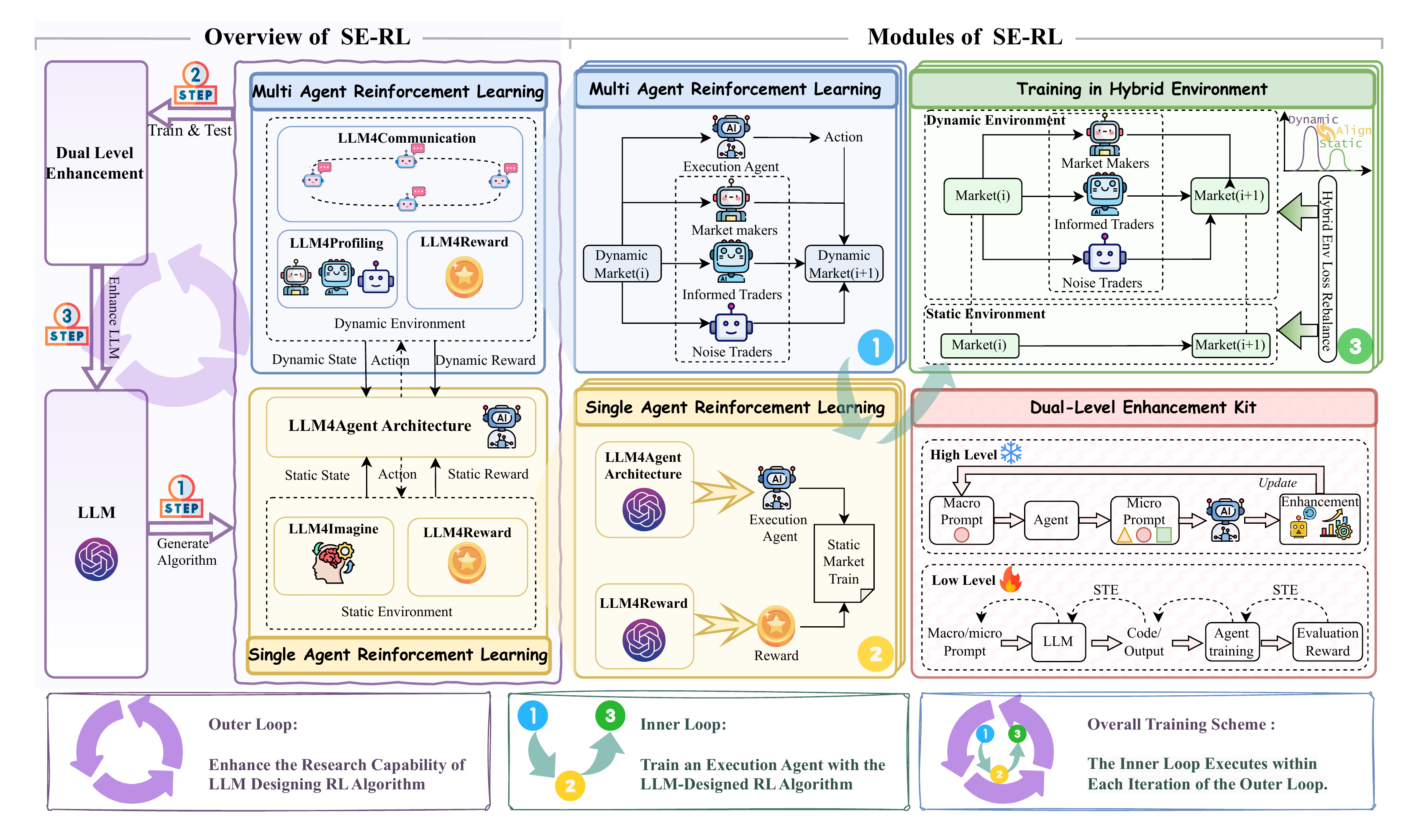
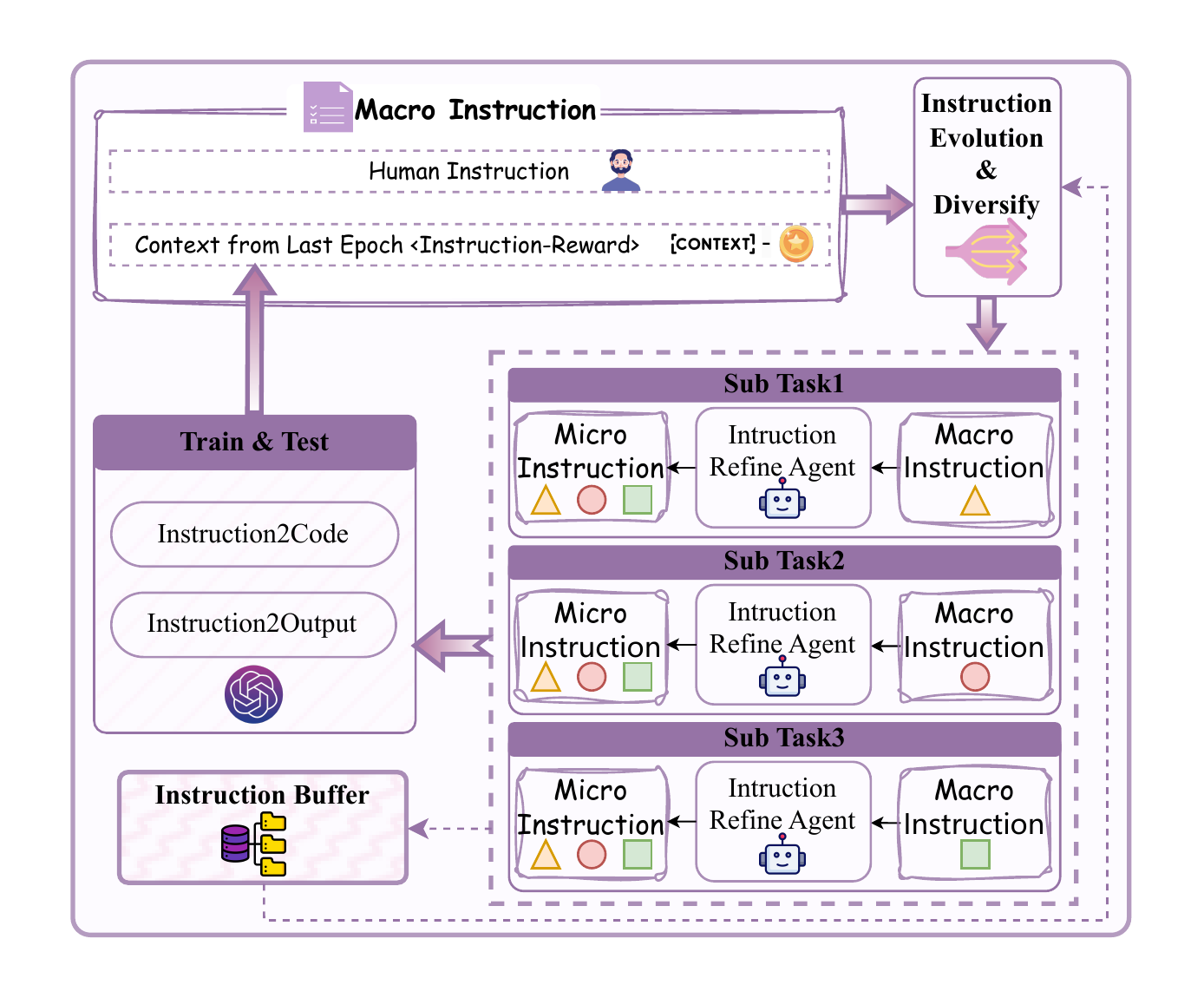
Motivation
Why SE-RL?
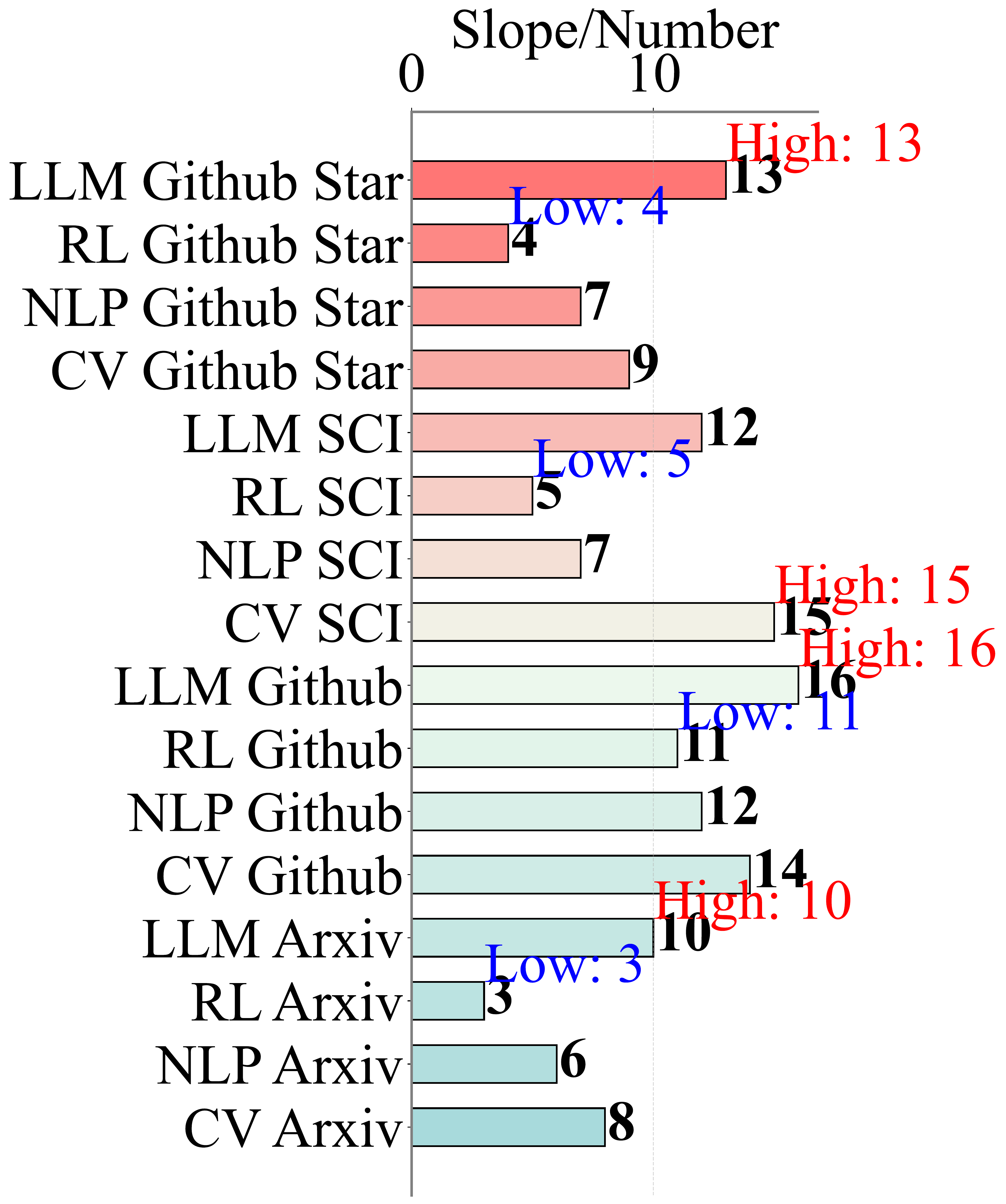
Slow RL Research Speed
Compared to rapid advances in CV, NLP, and LLMs, reinforcement learning algorithm innovation has been significantly slower. SE-RL automates the research process using LLMs, accelerating discovery.
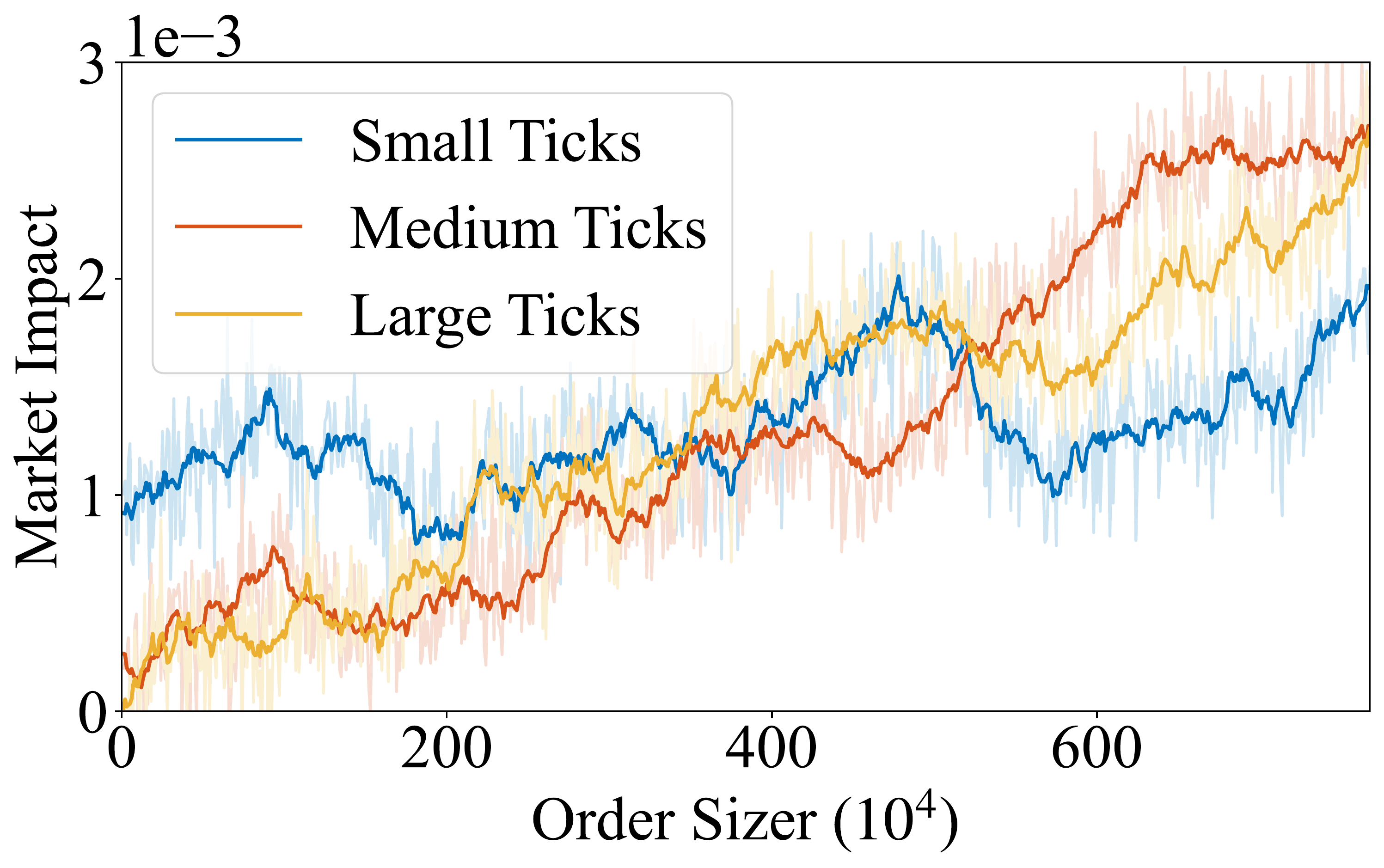
Unrealistic Market Assumptions
Existing RL methods rely on static market assumptions, ignoring the market impact of the agent's own actions. We build dynamic multi-agent simulators for realistic training.